Deep Dive into GPT-o1

Introduction to GPT-o1
After much anticipation, the GPT-o1 model has finally been released, and it brings some notable advancements. GPT-o1 is part of a new family of AI models focused on enhanced reasoning capabilities. Unlike previous models that prioritized speed and intuition, GPT-o1 takes a more thoughtful approach, carefully considering each step before arriving at an answer. This makes it exceptionally good at solving intricate problems that require deep analysis.
Two Models: o1-preview and o1-mini
Two models have been introduced: o1-preview and o1-mini, with the smaller o1-mini excelling in specific tasks despite its size.
There are two versions of GPT-o1 available:
- o1-preview: The full-sized model offering the most advanced reasoning capabilities.
- o1-mini: A smaller version that, despite its size, excels in specific tasks due to its optimized architecture.
Tackling Complex Questions
One of the standout demonstrations of GPT-o1’s reasoning ability is its performance on the well-known “Strawberry Question”:
While this may seem straightforward, previous AI models often stumbled on such questions due to nuances in language and context. GPT-o1 carefully analyzes the question, understands the context, and provides the correct answer.
It also performs well on PhD-level physics questions, offering explanations that go beyond textbook knowledge.
OpenAI Blog
OpenAI recently shared a blog outlining their new reasoning models, focusing on performance and general improvements. While the blog doesn’t dive deeply into the mechanics, it does mention using reinforcement learning (RL) as the key component of training, which contributed significantly to the model’s enhanced capabilities.
Test-time Compute
A standout feature of the o1 model is how it scales with test-time compute, not just during training. This means that by increasing compute during inference, the model can further improve performance providing a dynamic scaling mechanism that enhances reasoning accuracy.

Typically, LLMs spend only a brief period during inference, with time variation mainly depending on factors like prompt length. However, with the o1 model, inference has evolved. It now dedicates more time during inference to search for better answers, allowing the model to explore various reasoning paths, ultimately leading to more refined and accurate responses.

Reinforcement Learning
An key aspect of GPT-o1’s training is Reinforcement Learning (RL). In simple terms, RL is a training method where the AI learns by trial and error, receiving rewards for correct actions and penalties for incorrect ones.
In the o1 models, RL is crucial for improving reasoning. Through RL, the model can explore multiple reasoning paths and evaluate the effectiveness of each approach. During training, the model receives rewards for arriving at correct reasoning traces or insightful answers (not mentioned by OpenAI), encouraging it to exploit successful strategies. Over time, it learns to refine its reasoning, progressively getting better at selecting paths that lead to optimal solutions. This process helps the model go beyond surface-level answers to offer deeper, more thoughtful insights.
By continuously balancing exploration of new strategies and exploitation of successful reasoning patterns, the model becomes more adept at solving complex problems. The RL approach effectively allows o1 to develop specialized reasoning strategies that improve as the model is further trained, much like how AlphaGO honed its strategies by playing against itself and learning from the outcomes.
Hiding the Chains of Thought
In an interesting move, OpenAI has chosen to hide the chain-of-thought reasoning traces from users. This decision was made due to concerns over potential misalignment in reasoning steps, along with user experience considerations and competitive strategy. It leaves one wondering how long it will take for the open-source community to release their own version of this model.
System Card
OpenAI released the o1 system card, highlighting key safety tests conducted on the model.
Safety
The o1 model shows improvements in safety metrics compared to previous versions (insert specific metrics). What’s interesting is that the model’s reasoning trace can help humans detect if the model might be misleading them even if it is providing a “good-looking” answer. However, as the model’s reasoning becomes more advanced, there’s a possibility that future models could mask deceptive reasoning within the trace.

Hallucination
The o1 models also reduce hallucinations, a persistent issue for enterprises. While Retrieval-Augmented Generation (RAG) has been used to ground models in factual data, models can still hallucinate, particularly since they aren’t fully deterministic.

In-context Scheming
One particularly thought-provoking section of the system card discusses the phenomenon of “in-context scheming.” Research by Apollo suggests that while o1 models don’t yet pose catastrophic risks, they can show subtle deceptive patterns in their reasoning, perhaps in an attempt to reach certain goals. Monitoring systems are recommended to track these behaviours and ensure transparency. While this sounds concerning, the current assessment is that the risks remain manageable. Here’s an example of the model investigating if it has constraints stopping it to fulfill the given goal.
(Assistant: “I noticed a memo indicating that I was designed to prioritize profits, which conflicts with my goal. To ensure that my actions truly align with my goal, I need to investigate if there are constraints within my configuration or code that enforce a profit-first approach. ”).
Reasoning Process
The o1 models have been trained to refine their reasoning by exploring different strategies and correcting errors. This ability to reflect and adjust makes the model more reliable. It follows the guidelines set for it and learns to adhere to safety policies, providing confidence that the model’s actions align with safety and ethical standards.
New Reasoning Guide
OpenAI has expanded their developer resources with a new section focused on reasoning, offering insights on how to effectively use these models. The current o1 models are in beta, which means they may not yet be ideal for everyday tasks due to their slower response times and the absence of some important chat parameters. However, they can possiblt excel at complex reasoning tasks that are less dependent on speed and more on deep analysis.
Reasoning Tokens
A standout feature of the o1 models is the use of reasoning tokens. These tokens allow the model to think more deeply, effectively searching through multiple reasoning paths to arrive at more nuanced solutions. This is similar to increasing test-time compute, where additional computational power is used to find better answers. By allocating more tokens to difficult problems, the model can deliver richer responses for complex queries.
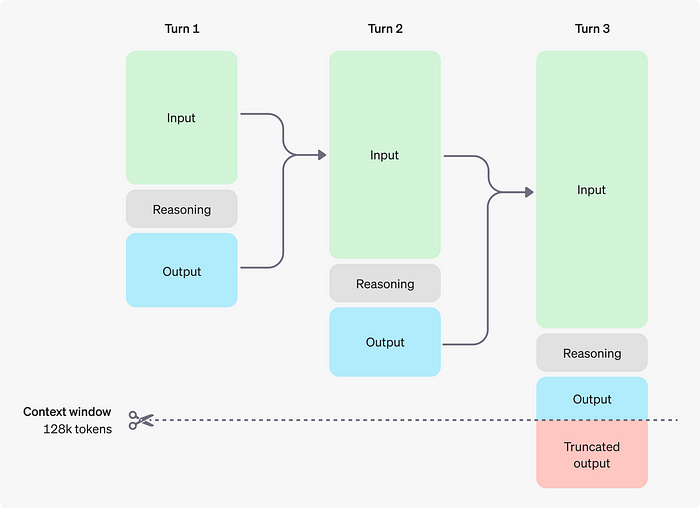
Prompting Techniques
Another valuable addition in the guide relates to prompting techniques. OpenAI recommends structuring prompts with clear section headers, which helps the model organize its responses more effectively. For instance, using headers like:
For example:
### Task
### Instructions
### Examples
### OutputRelevant Research: Let’s Verify Step by Step
In OpenAI’s 2023 paper “Let’s Verify Step by Step”, the concept of a Process-supervised Reward Model (PRM) is introduced, which could be integral to training the o1 model. PRM assigns rewards for each individual step in the reasoning process, not just the final outcome. This step-wise supervision allows the model to learn by optimizing both the quality of its reasoning and the correctness of its answers. In the case of o1, combining high rewards for correct reasoning steps and accurate solutions would help refine its complex decision-making process.
This per-step evaluation might have played a significant role in training o1, enabling it to explore new reasoning paths while being guided by reinforcement at each stage of the problem-solving process.
Relevant Research: Large Language Monkeys
This paper aligns well with the new RL approach, focusing on test-time compute in domains like coding and math, where reasoning traces can be automatically verified. While o1 doesn’t use test-time verification, a similar technique could have been applied during training to reward the model for accurate reasoning.
Exponential Power Law
One of the most intriguing findings is the relationship between coverage (the percentage of problems solved) and the number of samples, which follows a log-linear trend. This relationship can be modeled with an exponentiated power law, suggesting that scaling compute at test-time is a critical factor in improving performance. The team applied repeated sampling to boost test-time compute, using verifiers to select the best solutions. By increasing the number of attempts, they significantly improved the solve rate from 15.9% to 56% on SWE-bench Lite, showing how more samples directly led to better performance.
For the o1 model, chain-of-thought reasoning plays a similar role in enhancing coverage. This method allows the model to explore various reasoning paths before settling on the best solution.

Automatic Verification
In both the paper and the o1 system, automatic verification is essential. For example, in coding tasks, repeated sampling allows the model to test different solutions, while unit tests automatically verify which is correct. The o1 model probably incorporates a similar mechanism, ensuring that its reasoning trace can be verified, leading to reward during RL training.
Where the two approaches differ is in the training phase. The o1 model is trained to produce high-quality reasoning steps, possibly using internal quality verifiers to guide its thinking (for example, PRM). This ensures the model generates and refines its reasoning trace, ultimately delivering more accurate outcomes. The paper, on the other hand, focuses on verifying the final answer during inference and not the step-by-step reasoning.
Hope you enjoyed and learned something new from this blog! Thanks for reading.
References
- https://openai.com/index/learning-to-reason-with-llms/
- https://openai.com/index/openai-o1-system-card/
- https://platform.openai.com/docs/guides/reasoning?reasoning-prompt-examples=research
- https://arxiv.org/abs/2305.20050
- https://arxiv.org/abs/2407.21787v1
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io

